Build yourself a Git

Have you ever wondered how Git works? In this note we will incrementally build a version control system while taking inspiration from Git. Our focus will be on finding data structures to model revision lineage and version backups.
TLDR
It’s all about the directed acyclic graphs, fully persistent tries and layers of indirection wrapped in everything is a file.
Disclaimer
This note is neither intended as a Git usage or workflow guideline nor provide concrete code to make a binary compatible Git implementation. But this note will have thought experiments and pseudocode sprinkled in to motivate the reasoning for data structure choices. Consider this note an origin point for deeper rabbit holes to follow on implementation of distributed version control systems.
Tidbit
Have a look at Linus Torvalds' first commit and the README of Git from 2005. The fundamental data structures chosen at its inception has stood the test of time.
If you wish to make an apple pie from scratch, you must first invent the universe.
1. What is a Version Control System?
Before we get onto building a Version Control System (VCS), we need an idea of what we are trying to build.
We can view a VCS as a versioning backup system, that:
-
can keep the lineage of versions
-
can recover, compare and consolidate different versions
In addition to these basics, a realworld VCS ought to be scalable in:
-
handling millions of lines of code
-
handling revisions from developers distributed around the globe
Being the Linux kernel maintainer, this was certainly the requirements for Linus Torvalds in his implementation of a VCS, Git. Git takes capability for distributed workflow step further by providing a decentralized distributed workflow.
Another expectation from a VCS that can fall through the cracks is security. But as stated in the Git mailing list thread, security was part of the design goals from the beginning.
-
ability to prevent or detect corruption of data
2. Sheep following Git
Now that we have an rough idea of the requirements for what we are building, let’s get on to building this hypothetical VCS that I will call sheep, because this sheep will follow the path set by Git.
I need to clarify that Git may not be the be all end all of VCS. But Git is the VCS with most steam behind it at the moment. Mercurial is another VCS like Git that treats snapshots as first class citizens. Darcs and Pijul are other VCS that takes a different approach by utilizing patches as first citizens.
3. Intents and commands
Unlike a versioned file system where content is automatically backed up; in a VCS, all actions are performed when a user shows intent. Therefore the interface to our VCS plays a crucial role.
Let’s first list essential user intents and map each of them to our UI.
Intent to initialize a directory to be under version control
-
sheep init -
Since this is the directory that user performs their work on: Git calls this the working directory. We will also create a ".sheep" directory to store the metadata and we will call that the repository (repo).
Intent to include the changes to a file with next checkpoint
-
sheep add <file> -
Git calls this the staging area. Read more about it here. Only the changes that are staged will be included in the next checkpoint. Anything not staged will be considered as unchanged.
Intent to make a new checkpoint
-
sheep commit -
Here be dragons! Most of the magic happens in here.
-
When the user executes this command: a new backup version is created with all the staged content, and the version history is extended with the new checkpoint. We will see more about this extensively later on.
Intent to go back to a checkpoint and branch out
-
sheep checkout <checkpoint>andsheep branch <name>
Following image shows the basic Git (and hence Sheep) workflow, that essentially combines the above commands.
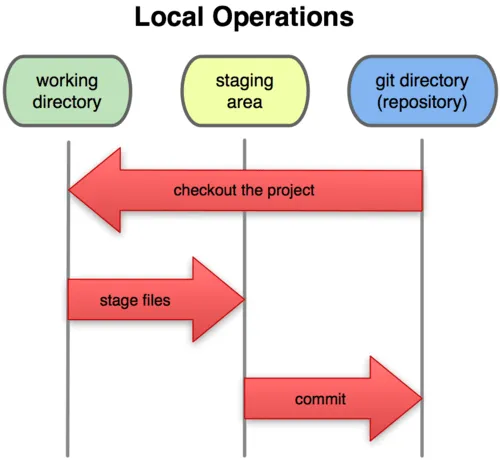
So where is the branching work flow?
It’s simply a matter of executing sheep checkout <checkpoint> to go back to a checkpoint; then sheep branch <name> to give the new branch a name.
And follow it up by sheep add and sheep commit workflow in Figure 1, “Basic local Git workflow from Git basics”.
Later on we will see how this is handled internally.
There is few other important intents/commands (diff, merge, fetch, push) that we will discuss as we go along.
4. sheep commit
From the implementation point of view, commit is where the magic happens.
As discussed earlier, user’s intent is to make a new checkpoint, which entails two ideas:
-
Make a backup of all directory content that is currently being tracked. Let’s call the view of the tracked directory content at a checkpoint to be snapshot.
-
Extend the version history graph with the information about this new checkpoint (and other metadata like author and date).
We can notice the above two ideas are essentially two steps where step 2 is dependant on information provided by step 1.
Let’s give each step a name: by calling step 1 as 'create-content-snapshot' and step 2 as 'extend-commit-history-graph'.
Now we can view commit as the composition of two functions create-content-snapshot and extend-commit-history-graph.
There needs to be an interface for the two functions to compose.
Observe: all that’s need by extend-commit-history-graph is a way to find the snapshot created by create-content-snapshot.
See the Listing 1, “Outline of commit code” to see how this interfacing can be achieved using pointer-to-snapshot.
function create-content-snapshot:
params: dir-content
returns: pointer-to-snapshot
function extend-commit-history-graph:
params: commit-history-graph, pointer-to-snapshot
returns: commit-history-graph
# and then
commit = extend-history-graph( ... , create-content-snapshot( ... ) )On each commit, create-content-snapshot function creates a new snapshot and feeds it to the extend-commit-history-graph function to create the extended commit history graph.
With the pieces of the commit puzzle in place, let’s start from the extend-commit-history-graph corner to see how everything will work.
4.1. Extending the commit history graph
Simple idea here is to keep track of the lineage of each commit.
4.1.1. Commit
In the previous section we discussed commit as a verb. Here we talk about commit as a noun.
From the previous section we know that a commit holds information about the snapshot.
Snapshot is a view of the directory content at a commit.
The goal of taking a snapshot is because we want to see all the changes to directory content after the parent commit.
We would also like to see who changed it, when they changed it, and why they changed it at a later point of time.
So to achieve this: think of a commit as a structure that holds (snapshot + parent commits + metadata: author, date and message). We’ll call this a commit object.
4.1.2. Commit history graph
Commit History Graph is the data structure that holds the lineage information of every commit. Basically it’s the life blood of our VCS. In implementation, Commit history graph is just the relative ordering created by bunch of commit objects that connect to each other like a chain.
4.1.3. Parent and Child commits
Let’s look at two sheep commits:
project/ $ sheep init
project/ $ vim README
project/ $ vim LICENSE
... <removed commands for brevity> ...
project/ $ sheep commit -a -m "Initial"
...
project/ $ vim quake.c
project/ $ vim Makefile
... <removed commands for brevity> ...
project/ $ sheep commit -a -m "Second"And how they can be represented in the graph:
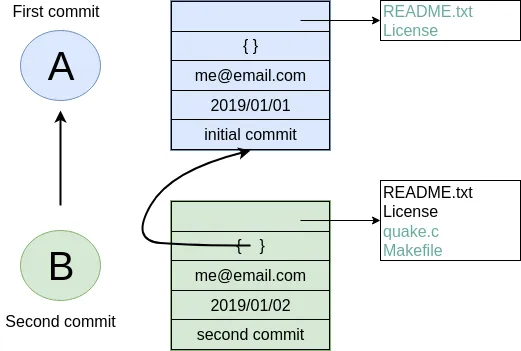
We’ll name the commits A, B in sequence for first and second commit.
A points to B? Or B points to A? Although we usually like to imagine the flow as forward in time, hence point from A to B; the answer is B points to A, because what we want from the graph is the history that led to a commit. We want to see the flow backwards in time. This decision lets us easily traverse backwards in time to find the ancestors and hence the changes that led to the current state of a file.
Observe in this model that A has no knowledge of the existence of B, meaning that a parent commit keeps no knowledge of the children commits. This allows us to remove, change and add children commits without mutating the parent commit. Since past commits have no dependance on future commits: by definition the graph that is generated will be a Directed Acyclic Graph (DAG).
4.1.4. Extending history
Let’s put in few more commits to our history:

Visually we can see that repo was at commit B, and then added commit C and then commit D. In implementation this can simply be achieved by having a pointer that always point to the currently active commit. Git calls this the HEAD. On the above history, since our currently active commit is D, current value of HEAD will be D (This is not exactly how Git does it, there’s one extra level of indirection. We will see about this in the branching section).
define function extend-commit-history-graph:
# The current HEAD will be the parent commit for the new commit
p = get value at HEAD
s = create-content-snapshot(...)
m = { read metadata from user environment }
c = create-new-commit-object with (p, s, m)
# give a unique name to 'c' and save it in the repo (./sheep/objects/)
# now update HEAD to c (we will revise this last step later on)Now if we were to implement sheep log, it’s simply a matter of traversing the pointers towards the ancestors while logging the metadata information in the output.
Until now we have been looking at simple linear history. Let’s see how branching can affect our commit implementation.
5. sheep checkout, branch and heads
5.1. Checkout
Let’s say the user wants to go back to an old commit and try some new changes.
This where checkout comes in to play.
Let’s imagine a scenario: Commit C is a Long Term Support (LTS) release. And in it there’s a bug they want to fix. To fix the bug user will just follow their intents.
project/ $ # user is at commit D now 1
project/ $ sheep checkout C 2
project/ $ vim test/main.c
project/ $ sheep commit -a -m "Update tests"
project/ $ vim quake.c
project/ $ vim CHANGELOG
project/ $ sheep commit -a -m "Fix super nasty bug" 3In Figure 4, “Checkout and extend” we can see how it’s represented internally at each (1), (2), (3) instances above:
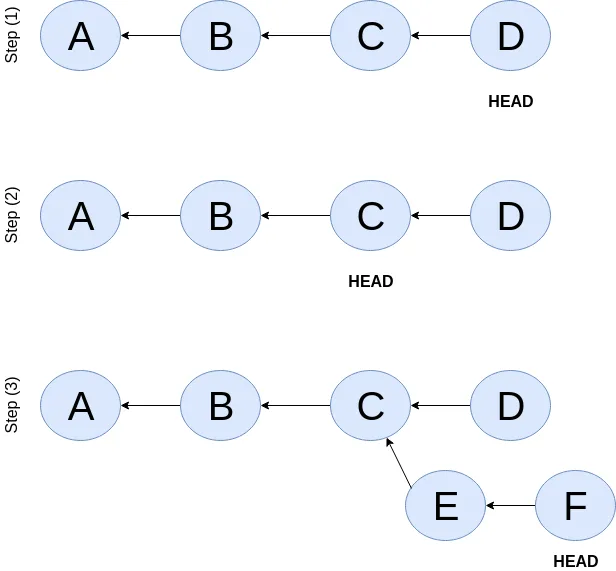
In implementation, checkout is simply to update the HEAD to a given commit and
recreate the directory content using the snapshot pointer in that commit.
5.2. Branches
Why do we need to support a branching workflow?
In Figure 4, “Checkout and extend” visually we can see the branch out at commit C. We need to support this kind of workflow because not all changes are sequential. One of our goals from the first section was to: let contributors work independently without synchronization at every commit. The system that we have discussed up to this point can already support a branching workflow. Is there more to be done? Yes there is. But not much.
We can see that there are two branches that has D and F as their tips. If the user wants to switch between the latest commit of each branch, with our current system they have to remember their exact commit name. But we can do better, with a simple layer of indirection.
Since our problem was that user has to remember the name of the commit at every branch tip: we introduce a layer of indirection, that will point memorable names to commits. In Git terms, this layer of indirection is called refs.
Branch names are just pointers to commits that follow along as the commit history graph extends. In addition we can notice that HEAD concept we discussed before is almost too similar to this branch concept. Git integrates the HEAD concept with the branches concept. Internally Git calls local branches as heads with in refs.
project/ $ sheep checkout -b $some-branch-name
project/ # Updates the HEAD pointer to point
project/ # to a branch (a local head in refs) that points to a commit
project/ # ... and follow same procedure as before
project/ $ <... make some changes ...>
project/ $ sheep commit -a -m "Super duper changes"
project/ # Revise our pseudo function: extend-commit-history-graph so that it
project/ # looks at the HEAD and follows the pointer to the
project/ # branch which points to a commit.
project/ # Uses that value as the parent commit,
project/ # and update that value with the name of the new commit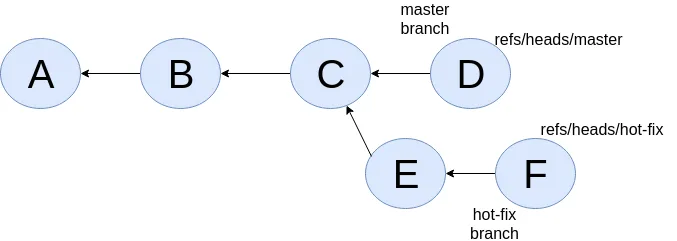
Heads or branches are the entry points to our commit-history-graph. That’s why in Git,
if you git checkout <random-commit>, it warns about detached head.
Unless you make a branch head at the detached head, any commits you make from a detached head will be lost in the sea of commits, as Git has no references to access them later.
Later on Git garbage collector will sweep off these detached commits (commits not accessible by any ref).
6. Decentralized distributed-ness
Until now we have only focused on local operations and not focused about the Distributed-ness of our VCS. That is because our plan is to have a symmetric view from the point of branches. Simply put we view a remote repo as a namespaced collection of branches.
A main goal of branches was to enable parallel work that need not always be synchronized. In that sense remote repo branch is just another branch to our local repo.
With this model of branching workflow we have set the roots for a decentralized distributed (version control) system.
Internally local branches are called heads, remote branches are called remotes. And they are both handled as refs.
6.1. What is shared between the repos?
In the distributed world we do have to be careful about the shared data. In our VCS the whole commit history graph is a globally shared data structure.
And hence:
-
commit objects and branch pointers
-
and also snapshot objects
are shared.
As a globally shared data structure we want our commit history graph to be a persistent data structure.
Why? Because if it was an ephemeral data structure we will need to complicate our implementation with synchronization primitives so that information about commits are not lost. For a thorough explanation, watch "Value of values" by Rich Hikey.
Immutable values aggregate to immutable values. Since we want a persistent data structure, if we make commit objects and snapshot objects be immutable, the commit history graph will be an immutable persistent data structure as well.
We can be glad that the commit objects, that was discussed in the previous sections were not relying to be mutable.
In extend-commit-history-graph we create a new commit, and extend the graph with a new commit.
Note that the commit history graph is a fully persistent data structure (every version can be both accessed and modified) if we consider that commits are the entry points.
But, since we use the branch heads as the actual entry points and because branch heads are mutable, the commit history graph is just a bit away from being a fully persistent data structure.
Basically this means that we have no versioning for the commit history graph it self.
Read up on git reflog to see how Git tries to circumvent this.
Are we still staying compatible with Git? I thought git rebase rewrites history.
Yes, we are still being compatible with Git.
Commands like git commit --amend, git rebase rewrites history by recreating the commits.
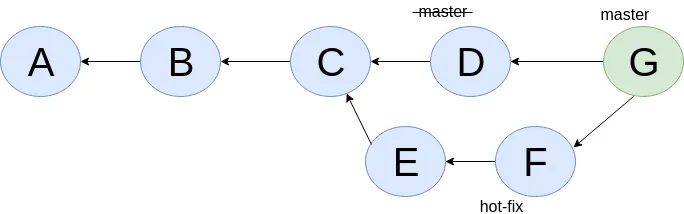
Using commit history from Figure 5, “With branch heads”, let’s see the end result of doing rebase hot-fix branch onto master branch.
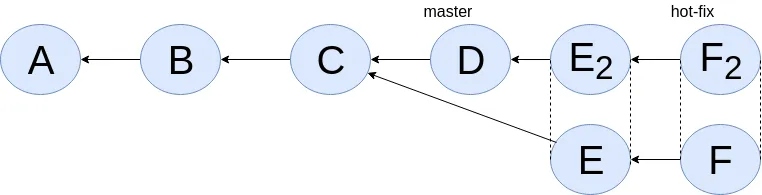
E2 and F2 is E and F respectively after being reapplied on the tip of master branch. Since E and F becomes detached heads they will eventually be garbage collected.
It’s recommended to never do rebase on a public branch for the reason that we destructively update the branch pointer to a totally new branch, which can cause problems down the line when syncing back with the public.
6.2. sheep fetch and sheep push
fetch and push are the commands that will show the users intent to synchronize.
On a fetch, we will fetched the commit history graph from a remote.
On a push, we will push our commit history graph to a remote.
Fetch needs read access and Push needs write access to the remote repo.
For simplicity let’s focus on fetch. Same concepts can be applied to push with slight variation.
Since we are aiming for a symmetrical view across remote and local repos: fetch will download all objects from the object stores (commit and snapshot) and refs without breaking any invariants on the destination repo.
6.3. Fetching refs
Fetching refs mean that we are getting all the entry points to the commit history graph in the remote repo. Since these pointers are mutable we have to be careful on sync, so that we don’t lose information. To prevent overwriting local heads, we sync remote refs with a namespace. And then let the user merge in the remote content with the local content at their leisure.
6.4. Fetching commit objects
Collect all commit objects that are accessible from remote’s entry pont(s) and put them all with the commit objects currently on the local repo.
(Git takes an extra step here by compressing similar files called pack files, so that we transfer less over the network. But for sheep let’s ignore that for the sake of simplicity.)
To implement this we need to concretize some ideas that we glossed over during extend-commit-history-graph.
6.5. The content addressable storage
First we need a place for our commits to reside on the disk. A database for our commit objects. And an api to get and create commits by a name. Basically we need a key-value storage. Git following the true Unix ways, uses the file system structure. Simply: filename as the key, and content as the value.
But remember that during a fetch we sync all commits from a remote repo into local repo. That every commit should have its own unique name. Looking at the problem in a different way: we need a way to see if a commit with same content already exists in the local repo. Basically we need a way to uniquely identify each distinct piece of content. How to easily check whether two contents are the same without having to scan the whole length of the content? Hashing!
Content hashing to the rescue. Get a hash of the object and that will be the name/key of that object and the value will be the object itself. Git calls this the content addressable storage and resides in (.git/objects/)
As discussed before commit objects are immutable hence, there will be no destructive updates on the commit and hence no inconsistent keys.
If we use cryptographic hashing, we are able to attain the Security goal of Git from the top section. By using cryptographic content hashing we are feeding two birds with one little grain. Observe the similarities of our commit history graph to a Merkle tree.
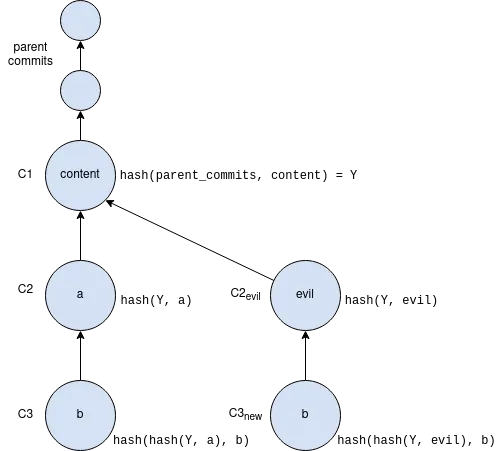
Figure 7, “Viewing Commit History DAG as a Merkle tree” shows that if an attacker tries to modify history by falsifying a commit (C2) they will end up creating a new branch out instead. As long as 'a' and 'e' are different C2 and C2evil will have two different commit hashes. By using a cryptographic hashing mechanism we can ensure that it will be hard for an attacker to falsify an 'e' that matches the hash with 'a'. Implying that C3 and C3new will have different hashes. So we can detect any corruption just by observing at the tip of the branch.
6.6. Back to: fetching
Now that we have the Content addressable storage, fetching commit objects is just a matter of downloading all commits accessible from the remote branch access points on to the local repo. Due to to our hashing mechanism we can ensure that we will not corrupt commit objects in the local repo. (We assume that hash collisions are highly unlikely)
Once we have all the commit objects from the remote repo, we just use the remote refs (or remote branch pointers) to access the Commit History Graph that the remote repo sees.
7. Back to: sheep commit
After a long detour we are back on track to our main command sheep commit.
7.1. Revising: Extend Commit History Graph
With the extra knowledge we gathered, we need to revise our algorithm for extend-commit-history-graph function.
define function extend-commit-history-graph:
# The current HEAD will be the parent commit for the new commit
# HEAD can either be a commit or a ref
if HEAD is a branch ref:
pc = get value at branch ref
else:
pc = get value at HEAD
s = create-content-snapshot(...)
m = { read metadata from user environment }
c = create-new-commit-object with (pc, s, m)
commit_name = crypto-hash(c)
write-file(directory="./sheep/objects/", filename=commit_name, content=serialize(c))
if HEAD is a branch ref:
update the value of branch ref to --> commit_name
else:
update the value of HEAD to --> commit_name
return commit_nameNext up is implementing create-content-snapshot.
7.2. Create content snapshot
Let’s remind our selves what we need from this step:
Make a backup of all directory content that is currently being tracked.
Few important requirements for snapshot from the previous sections:
-
Need to provide a pointer to be used in a commit
-
Snapshots should be immutable: so that same commit does not point to different snapshot contents at different points of time
7.2.1. Naive implementation
snapshot_name = create-unique-name-for-snapshot()
create directory to store snapshot
copy all tracked directory content in the repo to the new directory
return snapshot_name; # to be used by extend-commit-history functionWe can reuse some concepts from the earlier section:
-
A snapshot is immutable: therefore we can use content hashing to help create a unique name
-
We already have a storage for content addressable storage where hash of the content is the key, so we can reuse the place that we used to store commits (
.sheep/objects/)
With that we can modify the naive implementation to be:
snapshot_name = get-total-hash-of-the-content-being-tracked()
create directory named by 'snapshot_name' in ./sheep/objects/
copy all tracked directory content in the repo to the new directory
return snapshot_name; # to be used by extend-commit-history functionThis is a fine implementation of the interface of create-content-snapshot.
And conceptually we are done with sheep commit.
But we can see that this naive method will cause excessive duplication, because in practice we expect there will be lot of common content between two different commits. Since we make full backup of directory content with each backup we are not using space efficiently.
7.3. Trying a better implementation: intuitive attempt
The intuitive solution here is just store only the differences (diff). When we say differences between the snapshots we need to focus on:
-
Differences in content (edits to file contents)
-
Differences in directory structure (add/remove directories)
Let’s say we model the diff as a function that brings the parent commit’s snapshot to the child commit’s. And store this function in some serialized format that we can apply later to reconstruct a version. Space problem solved. But this method has a major effect in performance for the user intent: going back to a previous revision.
Because to reconstruct a previous revision of a file we have to go back to it’s origin commit, and reapply all the differences down its lineage chain until the final version is constructed. Essentially reconstruction per file becomes O(ND) time complexity where N is the length of the lineage chain and D is size of the diff (in worst case D is the size of the file itself).
This is an alright solution if we just want to archive, but we can do better for sheep.
7.3.1. Better implementation: just like git
To find a better way, we remind ourselves a property from the naive implementation.
The snapshot that got backed up (in to .sheep/objects/<hash>) is never going to be modified by another commit.
The snapshots are immutable.
Hence we can use a functional data structure to represent the snapshots, which opens up for the great deal of literature on implementations with much better space and time complexity than our naive implementation.
On that note Purely Functional Data Structures by C. Okasaki is a must read.
7.3.2. Trying a trie
We have to model our file system into a data structure. For that if we view the file system as a key-value storage where the keys have a hierarchical structure, then the Trie data structure naturally fits in as a data structure of choice.
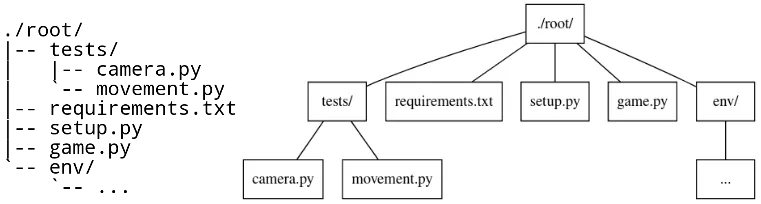
In our implementation the project tree trie can be viewed as a recursive data structure: a rooted tree where the tree can hold tree objects or blobs. Tree object represents a directory and Blob represents a file. Refer to Git Objects for further fine grained information.
7.3.3. Fully persistent Trie
In the project tree trie definition we came up with: "holds" can be thought of as "point to".
Most pointer based data structure like this can be made in to a persistent data structure by the path copying technique.
There are other techniques, but sheep will follow along with Git.
Few other reasons for using path copying:
-
Path copying stays consistent with the way we implement persistent Commit History Graph.
-
We will later see how it integrates back to the Security goal
Read here for explanations on path copying and other techniques.
Path copying means we copy the path only for the values that changed.
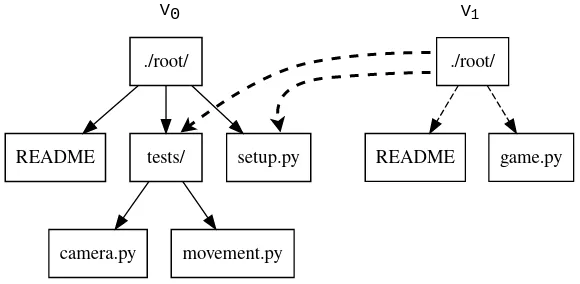
In Figure 10, “Changing tests/camera.py file from V1 snapshot leading to V2 snapshot” we can see that in V1 snapshot has made a copy of the path to README because README file was changed in this snapshot. Meanwhile "tests" directory and "setup.py" were kept as is, so those pointers are reused.
One more example to show off path copying in action:
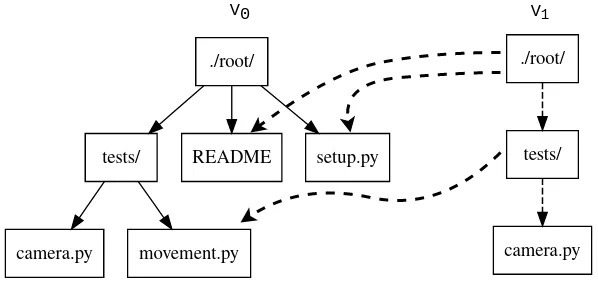
As we can see this solves our duplication problem in create-content-snapshot, because we can reuse the pointer for any tree/blob objects that were not changed.
7.3.4. Objects and Pointers of the trie
To get the most reuse from our persistent trie we want granular objects. As discussed before thinking directory as tree objects and files as blob objects gets us these granular objects.
Now we need a place to store these objects and the location can act as the pointer to our objects. Remember that we need snapshots be immutable, hence the trie is immutable and therefore tree and blob objects are immutable.
This means we can reuse the same strategy that we used with commit objects.
That is to use the content addressable storage.
Key of a tree or blob will be the hash of its content.
Note that key of a blob is dependant only on the hash of its content, a rename would not affect the blob (This will help us track renames when doing diff).
Hash of the root of the trie will be the snapshot pointer that will be used in creating a commit object.
Notice: that we are treating blobs as opaque objects. We are not trying to store the diff between the blobs that could be almost the same, between revisions. We are still not using our space as efficiently as possible. This becomes an issue especially when we are transferring content over networks. As briefly touched upon before, Git uses something called pack files, you can read more about it here.
If we use cryptographic hashing as with commits: we get a Merkle tree at the snapshot level. This means any change in content will be reflected as a new change leading to new a snapshot version. Note that we are not able to stop someone from forcefully modifying the content inside an object. But a simple integrity check by hash checking will let us identify offending objects.
As with commit objects: on a sheep fetch we can simply download all the tree/blob objects reachable from the remote commit history graph access point(s).
7.3.5. Reducing pointer hops with a cache: index
One downside of all these objects and pointers in the trie method is that, to see the latest committed version of a file we have to hop through all these pointers. Since each pointer dereference consists of disk read, there will be a major performance hit.
To get solve this problem we will introduce a cache. Git calls this cache the index. Whenever the user changes the current active commit: we will create the index, by fully traversing the trie snapshot associated with that commit and make a full list of paths seen by that commit.
This let’s us
-
Efficiently implement a command like
sheep statussimilar togit status. -
On a commit we can efficiently build up a snapshot trie by only copying the paths that have any changes.
Linus' README from the first commit explains this concept thoroughly.
Later versions of Git combined the index as a cache with the staging area idea.
8. sheep add and the staging area
During create-content-snapshot we glossed over the "content being tracked" part.
Since sheep add determines what content needs to be taken into a snapshot, let’s discuss this further.
First we need to remind ourselves the intent behind sheep add.
Intent to include the changes to a file/directory with next checkpoint
This is a valid intent, because sometime we want to split the changes under different commits. So the user only wants the changes in the staging area to be taken in to the snapshot with the next commit.
We can think of implementing sheep add as merely a way to set a marker for a file / directory entry in the index cache.
If they are new files we can also add those entries to the index as a different section.
9. Back to: sheep commit
9.1. Revised: Create content snapshot
sheep add combined with staging area (aka the index) greatly simplifies the job of create-content-snapshot.
Now we only need to check the entries marked in the 'index' to be included as changes in the snapshot.
Let’s write some pseudo code:
define function create-content-snapshot:
s = empty tree
for each change marked on the index:
update s with adding the path by looking at the content in working dir
store the new objects in the content addressable storage
for each all other entries on the index:
update s by reusing the same pointers
key = hash(s)
include this key and s in the content addressable storage
update the index so that all entries are marked as unchanged
return the key # to be used when creating the new commitWith the completion of create-content-snapshot we now have completed the full puzzle of sheep commit.
10. sheep diff and merge
We have come to the last two commands that we had planned out for sheep.
Diff and merge are essential parts of a VCS, that actually needs note each for themselves.
For the time being we’ll briefly look at each and have pointers further reading.
10.1. diff
Diff is simply to diff two snapshots. Conceptually same as diffing two directories. There are few minor optimizations we can make due to the usage of content addressing technique. If we look at two hashes and they are the same then we can ignore having to diff. This optimization can be done even at the tree / directory level because of the hash tree structure of the trie.
For easier diffing Git choses to store tree objects sort and store the pointer list. This means that tree object diff will only be of O(n) worst case time complexity. We have no way of controlling the blob diffs because the structure of that content is considered opaque from our VCS standpoint.
The first implementation simply leveraged the system diff executable via a call to popen in show-diff.c. diff is a very famous and ubiquitous tool in the Linux world originally developed in the early 1970 for Unix. Its first version used Hunt-McIlroy algorithm. The core algorithm was later notoriously improved thanks to the work of Eugene W. Myers and Webb Miller, work extensively document in the papers: An O(ND) Difference Algorithm and its Variations by Eugene W. Myers and A File Comparison Program by Webb Miller and Myers.
Algorithmica "An O(ND) difference algorithm and its variations" (1986)
For the basic implementation we can just reuse the builtin Unix diff, but we have to keep in mind there’s whole big world of advance diff algorithms.
10.2. merge
If branching is yin. Merging is yang.
It doesn’t matter how much we can branch out, we need a way to consolidate these diverging changes.
And that is where merging comes in. For sheep will only focus on true merges in this note.
10.2.1. User intent
-
Intent to merge diverged changes of a project in to one coherent result.
-
sheep merge <b>: Merges branch b changes on to the current branch
10.2.2. Commit History Graph
First let’s look at how a merge looks like in our commit history graph.
G is a merge commit. It’s special only in the sense that it has two parent commits. Everything else that we know about commits apply here.
10.2.3. 3 way merge
For sheep will chose two do three way merge following the path of Git.
3-way merge has shown more success in performing automatic merges compared to 2-way merge.
3-way merge means, the user gets access to two conflicting pieces of content and the base content where they both were derived from.
Let’s see how to achieve this in sheep merge as seen on Figure 11, “Merging 'hot-fix' on to 'master' branch. G is a merge commit.”.
10.2.4. LCA
We are trying to merge 'hot-fix' branch (commit F) into 'master' branch (commit D). Visually we can see that commit C is the base commit that derived both F and D. But more formally this commit C is defined as the Lowest Common Ancestor of the commit history DAG.
Naive algorithm for finding LCA:
Start at each of nodes you wish to find the lca for (a and b)
Create sets aSet containing a, and bSet containing b
If either set intersects with the union of the other sets previous values (i.e. the set of notes visited) then that intersection is LCA. if there are multiple intersections then the earliest one added is the LCA.
Repeat from step 3, with aSet now the parents of everything in aSet, and bSet the parents of everything in bSet
If there are no more parents to descend to then there is no LCA
When there are crisscross merges involved, there can be multiple LCAs. The default solution to this problem in Git is to do recursive LCA on these two until we find a single LCA. See documentation for git-merge-base.
10.2.5. Trie merge
Once we have a base commit and the two conflicting commits, we are ready to do the merge of directory content.
We can think of trie merge as a merge function for key value storage, because trie is basically a key value storage where keys have a hierarchy.
To investiage this let’s zoom in on commits C, D and F in Figure 11, “Merging 'hot-fix' on to 'master' branch. G is a merge commit.”.
C is the common ancestor.
D is the current tip of master branch; F is the current tip of hot-fix branch.
Let’s see how the merged commit G can be derived from C, D and F.
I have used (*) stars to mark which content were actually changed from C.
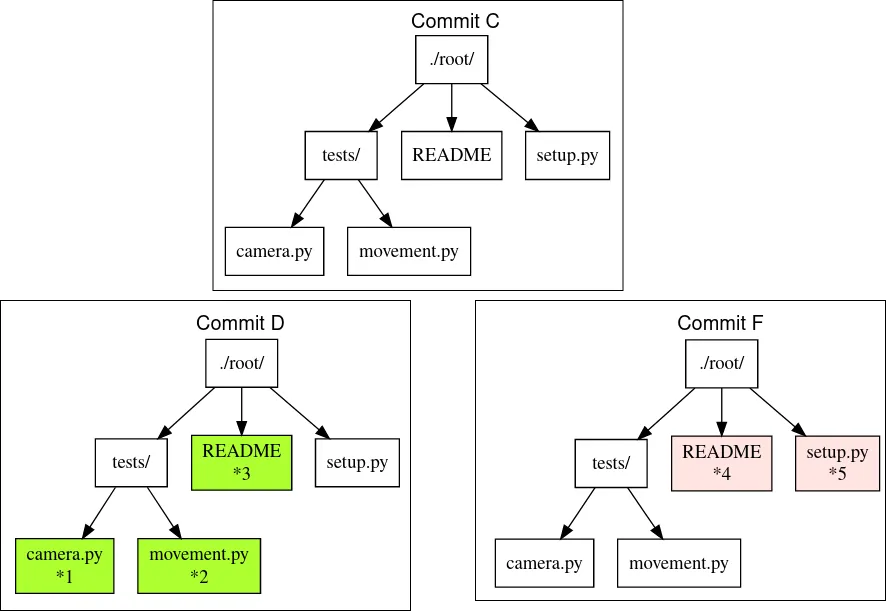
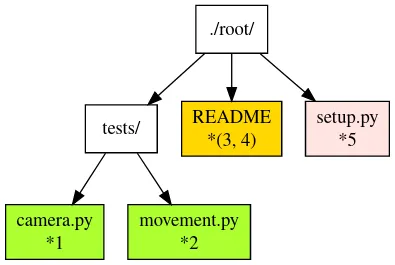
We do a diff of the C’s commit snapshot against D’s to see what has changed from C to D. Then we do a diff of C’s commit snapshot against F’s to see what has changed from C to F. These diff we will call patches. Now we use merge algorithm to auto merge content that never conflicted.
For example in Figure 12, “View of the snapshots at commits C, D and F.”:
-
*1, *2 only changed on 'master' branch therefore we can auto merge these changes in to the final snapshot.
-
*5 only changed on the 'hot-fix' hence we can auto merge this change into the final snapshot as well.
-
*3 and *4 shows that README was changed in both branches: hence a conflict on that file.
-
Think about how we should handle auto merges for: deletes and renames
At a conflict, merge will pause the merge and do a diff and put helper markers to identify the base, ours (current branch) and theirs (merging branch) changes.
Once the merge conflicts are resolved, merge will resume to make a commit with this new snapshot view and this commit will point to the two parent commits.
Read into git merge documentation to see the extra functionalities that it brings to the table.
With that we have reached the end of essential commands we planned out for sheep.
11. Final remarks
Say no more to rm -rf .git. Say hello to rm -rf .sheep.
11.1. Bird’s-eye view
If we take a bird’s-eye view of what we have done until now: we can see that we have built a database.
A database with a branching based concurrency control mechanism.
Taking the notion of database as value (talk by Rich Hikey), the value we built for sheep is a trie.
But we focused on a trie merely because our aim was to build a VCS.
Using just content addressable storage and ref indirection layer as our building blocks we should be able to build almost any fully persistent data structure.
Mirage OS Irmin project is an exploration of this idea.
11.2. Conclusion
In this note we managed to split Git and its concepts into manageable pieces so that we can build it from the ground up. More importantly while building the concepts step by step, we tried to build up understanding by asking ourselves why at each step of the way.
If you are hungry for more VCS concepts: look into Pijul.
The main difference between Pijul and Git is that Pijul deals with changes (or patches), whereas Git deals only with snapshots (or versions).
There are several advantages to using patches. First, patches are the intuitive atomic unit of work. As such, they are easier to understand than commits. And actually, Git users often reason in terms of patches, displaying commits as differences between snapshots.
Patches can be merged according to intuitive formal axioms …